El Vault Sobrevive al Agente: Por Qué Tu Segundo Cerebro Necesita un Protocolo
La mayoría de segundos cerebros con IA viven en el prompt de un agente. El vault deriva mientras el agente olvida las reglas. brainkeeper pone las convenciones en una spec que el vault hace cumplir.
Montas el vault de tu segundo cerebro. Las carpetas, nombres y convenciones de etiquetado que te funcionan según cómo piensas. Después le enseñas las reglas a tu agente de IA, normalmente con un archivo de instrucciones tipo CLAUDE.md. Añades algunos comandos personalizados para las cosas que haces todos los días. La primera semana es magia. El agente crea notas con la forma adecuada que encajan en tu estructura sin que tengas que pensarlo.
Después empieza el drift.
En la semana tres el agente etiqueta una nota como meeting en vez de meetings/weekly-sync porque le salió natural en ese momento. En el mes dos olvida rellenar campos de metadatos en cinco notas durante una sesión larga. En el mes cuatro un log de proyecto aterriza en inbox/ porque el agente decidió que las “cosas en las que pensar” van ahí. En el mes seis estás dedicando los domingos a limpiar notas que el agente formó mal.
Las convenciones de tu CLAUDE.md son consejos. El agente las lee, y luego se aleja de ellas bajo presión de contexto o simplemente porque el siguiente token plausible no encajaba con la regla. Multiplica por cientos de notas y el vault es un caos silencioso.
Una versión distinta de este problema te golpea si en algún momento cambias de agente. Te mueves de Claude Code a Codex, pegas tu CLAUDE.md en su prompt, y las convenciones se resetean a una forma ligeramente distinta. Misma raíz: las reglas viven en el prompt del agente, donde cada agente (y cada sesión) las interpreta a su manera.
Tu segundo cerebro no debería depender de que el prompt se siga correctamente cada sesión, este año y el siguiente.
Los datos sobreviven a la herramienta. Vas a pasar una década con las mismas notas (o más; las notas más antiguas se remontan más atrás). Las convenciones que convierten un vault en un segundo cerebro en lugar de un cementerio de notas pertenecen a los datos, no al prompt de un agente concreto.
Este artículo va de qué pasa cuando te tomas esa idea en serio y reconstruyes la interfaz de tu vault como un protocolo.
El modo de fallo de “simplemente prompt al agente”
El primer movimiento natural es enseñar al agente. La mayoría de los setups de gestión del conocimiento de hoy funcionan así. Abres Claude Code, escribes un CLAUDE.md. Abres Cursor, escribes reglas. Abres Codex, escribes AGENTS.md. Las instrucciones viven en el runtime del agente. El vault son solo archivos; las convenciones son prompts.
Hace unas semanas escribí un artículo largo sobre este enfoque, Tu Vault de Obsidian Es una Base de Datos. Claude Code Es el Lenguaje de Consulta. Seis carpetas, un archivo de instrucciones CLAUDE.md, slash commands personalizados para las cosas que haces todos los días. Es un gran punto de partida. Es donde empecé yo.
Pero se rompe de cinco maneras concretas en cuanto empiezas a usarlo en serio.
Drift entre sesiones. Esta es la que la mayoría siente primero. “Sigue estas convenciones” es una restricción blanda. El agente puede añadir created: 2026-05-03 un día y created_at: 2026-05-03 al siguiente, dependiendo de qué presión de contexto le hizo olvidar. Las etiquetas derivan entre formas (meeting vs meetings/weekly-sync), faltan campos de metadatos requeridos, el mismo tipo de nota acaba en dos carpetas distintas según la sesión. Multiplica por unos cientos de notas y el vault es un caos silencioso.
Sin enforcement en el momento de escribir. Un prompt es un consejo. El agente es libre de ignorarlo. No hay nada en el bucle que diga “esta escritura falla si el frontmatter está mal formado”. Los datos malos aterrizan en el vault y se quedan ahí hasta que los encuentras.
Coste de descubrimiento en un vault de 1000 notas. Cuando el agente necesita encontrar todas las notas etiquetadas meeting, lanza un grep. Cada consulta empieza leyendo el vault entero. Cuanto más grande se hace el vault, más lenta (y más cara en tokens) se vuelve cada operación.
Race conditions. Estás editando una nota en Obsidian. El agente en otra ventana edita la misma nota. Una de las escrituras gana; la otra se pierde en silencio. No hay protocolo para “leí este archivo en mtime X, aborta si ha cambiado”.
Pérdida entre agentes (la versión que te tocará tarde o temprano). Tu CLAUDE.md está en la sintaxis de Claude Code. Codex lee AGENTS.md. Cursor lee su propio archivo de reglas. Cada agente tiene su propio formato de instrucciones y su propio sistema de slash commands. En cuanto pruebas un segundo agente, estás reescribiendo las convenciones en un dialecto nuevo cada vez. Esta es más rara porque la mayoría se queda con una sola herramienta, pero hace el mismo punto que las demás: las reglas en un prompt están atadas al runtime de un agente.
Esto no es teórico. Es lo que te encuentras cuando el enfoque manual escala más allá de cien notas y un solo agente. Lo que necesitamos no es un prompt más inteligente. Es una capa que se sitúe por debajo del prompt.
La capa que falta: una spec que pertenece al vault
Markdown ganó como formato para tomar notas porque es un formato, no un producto. Puedes abrir un archivo Markdown en cualquier editor de texto en cualquier sistema operativo. Puedes hacer grep sobre él, versionarlo en git, adjuntarlo a un email, pegarlo en una wiki. El hecho de que Obsidian esté construido sobre Markdown significa que Obsidian es reemplazable. Si Obsidian desapareciera mañana, tus notas seguirían abriéndose en vim.
YAML frontmatter ganó por la misma lógica. Es un contrato entre quien escribe y quien lee: la parte entre las líneas --- son datos estructurados, la parte de después es prosa. Cada herramienta Markdown que respeta este contrato lee el frontmatter de la misma manera. Hugo, Jekyll, Astro, Obsidian, VS Code con la extensión adecuada, tu script de Python a medida. Mismas notas, mismo frontmatter, mismo significado.
El formato del vault ya está resuelto. Una carpeta de archivos .md, YAML frontmatter en las notas gestionadas, un layout de carpetas que tiene sentido para humanos. Esa parte está cerrada.
Lo que nunca se cerró es el protocolo para acceso de IA. ¿Cómo sabe un agente dónde escribir una nota nueva? ¿Qué campos necesita el frontmatter? ¿Si delete significa “borrar del disco” o “mover a archive/2026/”? Hoy cada agente responde a estas preguntas de forma independiente, leyendo las instrucciones del usuario en el formato que ese agente soporta.
Las convenciones viven en tres sitios, y la diferencia importa:
| Dónde viven las convenciones | ¿Aguanta entre sesiones y agentes? | ¿Schema validado en cada escritura? | ¿Escala más allá de un usuario? |
|---|---|---|---|
El system prompt del agente (CLAUDE.md, AGENTS.md) | No | No | No |
| Tu cabeza | No | No | No |
| Una spec que pertenece al vault | Sí | Sí | Sí |
“Schema validado” se refiere al contrato estructural: campos de frontmatter requeridos, tipos, reglas de ciclo de vida. brainkeeper rechaza las escrituras que los violan. No fuerza convenciones semánticas como la forma del valor de una etiqueta (puedes seguir usando meeting o meetings/weekly-sync libremente; la spec no elige por ti), el naming de archivos, o si un log de proyecto “encaja” en inbox/. Cierto criterio se queda con el agente. Pero el suelo estructural ahora es no negociable, que es lo que faltaba.
Una spec que pertenece al vault es el único sitio que sobrevive. El agente va y viene. Las convenciones no.
Esto es lo que es brainkeeper. Un protocolo que vive junto a tus notas, expuesto a través de un servidor MCP. Cada agente de IA que soporta MCP obtiene automáticamente el mismo contrato del vault. Las convenciones ya no viven en el prompt de ningún agente. Viven en un JSON Schema y en una superficie de herramientas MCP con la que cada agente habla de la misma manera.
Presentando brainkeeper
brainkeeper son dos cosas: una spec, y una implementación de referencia en Python que distribuye un servidor MCP.
La spec
brainkeeper.yaml vive en la raíz de tu vault. Describe el layout de capas (seis carpetas estilo PARA por defecto, extensibles) y las reglas de routing. El SPEC.md que la acompaña define:
- Layer keys:
inbox,journal,projects,areas,brain,archive. Cada key se mapea a un nombre de carpeta (que puede ser00 Inbox,Inbox,inbox/, lo que quieras; solo declara una vez enbrainkeeper.yaml). - Contrato del frontmatter: cada nota gestionada tiene como mínimo
created(fecha ISO),updated(fecha ISO, ≥ created), ytags(≥1 entrada). Los campos extra pasan sin tocarse. - Reglas de ciclo de vida: escrituras atómicas, mtime guards en sobrescrituras, soft delete que mueve a
<archive>/<YYYY>/,updatedse refresca en cada escritura. - Plantillas: las plantillas por capa viven en
<layer>/_templates/, excluidas de la indexación.
La spec está en un repo público. Cualquiera puede implementar contra ella. Implementaciones en otros lenguajes serían bienvenidas.
La implementación de referencia
El paquete Python distribuye un servidor MCP con 13 herramientas en 3 capas:
Primitivas (operaciones de archivo): read_note, list_notes, write_note_atomic, move_note, delete_note.
Convención (consultas conscientes de la spec): read_convention, list_layers, get_template, resolve_path.
Semántica (consultas a nivel de spec): find_by_tag, find_orphans, validate_frontmatter, update_frontmatter, list_tags.
Cada operación pasa por la spec. write_note_atomic valida el frontmatter contra el schema; la escritura falla si está mal formado. delete_note(soft=True) mueve a la carpeta de archive según la spec. find_by_tag consulta un índice en memoria que vigila el vault y se actualiza cuando los archivos cambian, así que un vault de 10.000 notas responde a consultas de tag en milisegundos, no en segundos.
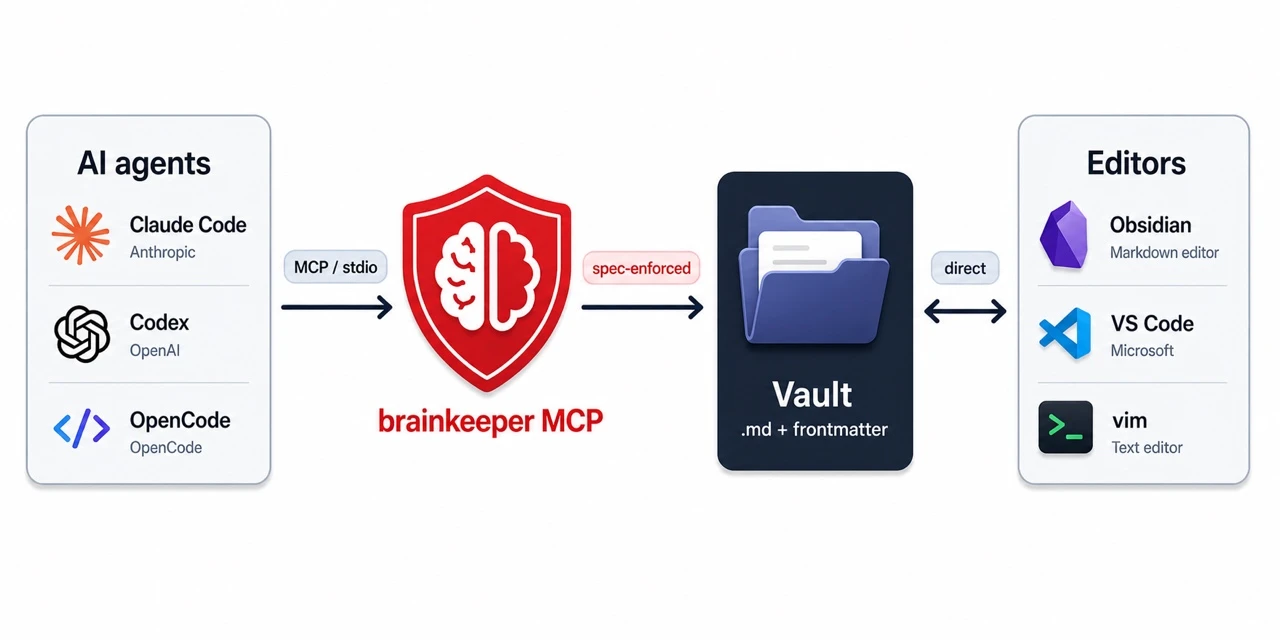
El MCP es la capa de cumplimiento de la spec para el acceso de los agentes de IA. Los humanos (tú, en Obsidian o VS Code) siguen escribiendo en el vault directamente; nada cambia para el lado humano. Solo la ruta del agente está mediada.
Tutorial: 5 minutos para probarlo
Cinco minutos desde pip install hasta tu primera nota gestionada por un agente.
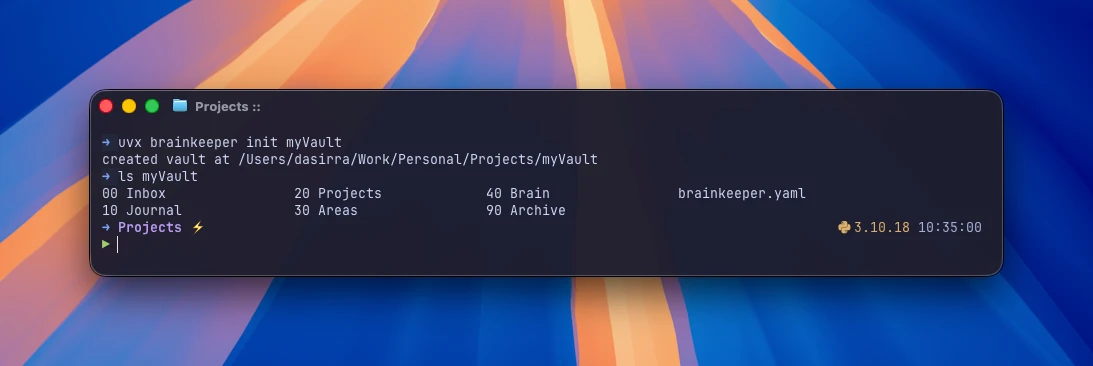
1. Inicializa un vault
uvx brainkeeper init ~/MyVaultEsto deja un brainkeeper.yaml en la raíz y crea las seis carpetas de capa con sus nombres por defecto. Abre el YAML si quieres renombrarlas (p. ej., inbox: "00 Inbox" en vez de inbox: "inbox"); la spec te deja personalizar libremente.
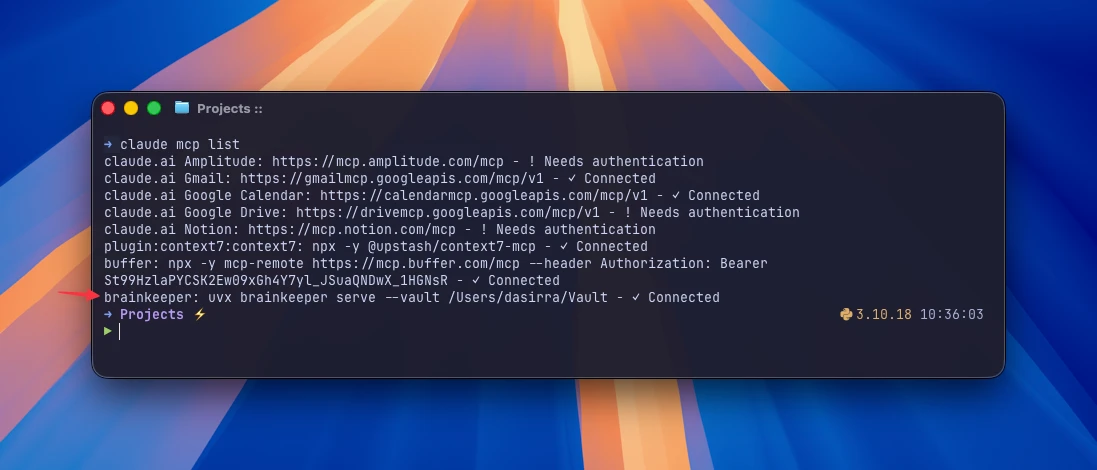
2. Regístralo en tu agente
Para Claude Code (el comando de registro varía por agente; el resultado es el mismo):
claude mcp add --scope user brainkeeper -- uvx brainkeeper serve --vault ~/MyVaultuvx descarga brainkeeper desde PyPI bajo demanda y lo ejecuta. Sin instalación, sin virtualenv que mantener. Reinicia tu agente y gana un toolset brainkeeper.
3. Pruébalo
Pídele algo a tu agente:
“Captura esto como una nota: debería comparar ACP y MCP para orquestación de agentes.”
El agente llama a resolve_path (la nota nueva se rutea a inbox/), write_note_atomic (con frontmatter que valida) y te confirma. La nota está en disco antes de que el agente termine la frase.
Después, en lenguaje natural:
“Muéstrame las notas que hablen de MCP en el vault.”
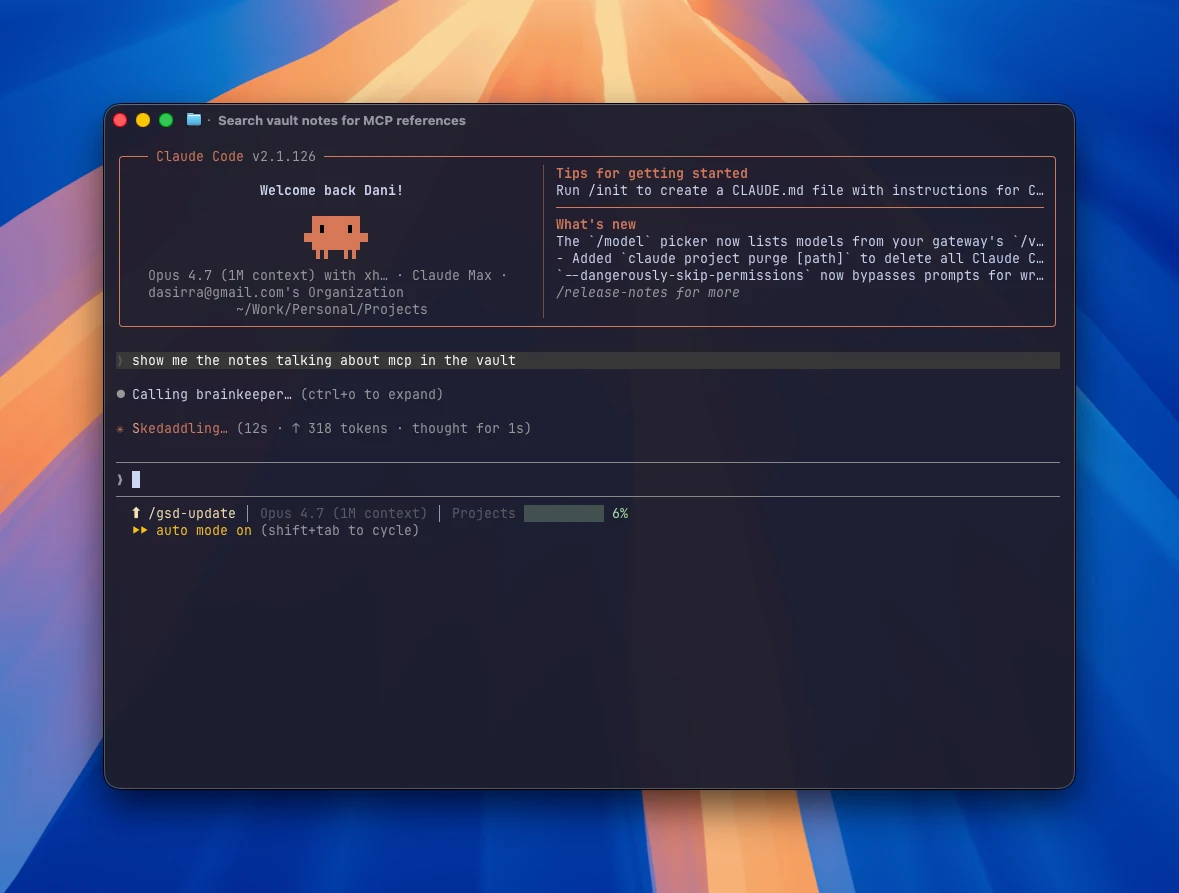
El agente llama a find_by_tag contra el índice en memoria de brainkeeper. El MCP en sí responde en milisegundos; el tiempo que esperas en realidad es el agente razonando cómo formular su respuesta, no la consulta.
Después:
“Muéstrame los huérfanos.”
El agente llama a find_orphans(), que saca a la luz cada nota del vault que falla la validación de la spec. ¿Le falta updated? Listada. ¿Formato de fecha incorrecto? Listada. ¿created posterior a updated? Listada. El vault te dice qué hay que arreglar.
4. La parte importante
Ahora registra el mismo servidor MCP con un agente diferente. Codex, OpenCode, lo que sea que hable MCP. El mismo comando uvx brainkeeper serve --vault ~/MyVault, registrado a través del setup MCP de ese agente.
El mismo vault. Las mismas convenciones. El mismo toolset. El agente del otro lado no tiene CLAUDE.md, ni archivo de reglas, ni slash commands. No los necesita. Las convenciones viven en la spec, no en el agente.
Esto es lo difícil de transmitir por escrito. Funciona. Instalas brainkeeper una vez, apuntas cada uno de tus agentes a él, y todos se comportan igual contra tu vault. Cuando salga un agente nuevo el próximo trimestre y quieras probarlo, la migración es el comando de registro. Eso es todo.
Lo que esto desbloquea
Cuatro cosas cambian cuando las convenciones salen del agente y entran en la spec.
Consistencia que no deriva
Esta es la mejora que la mayoría siente primero. Cada escritura pasa por validación de schema. El agente no puede inventar nombres de campo nuevos. Las reglas de routing eligen la carpeta correcta independientemente de lo que el agente piense que “encaja” hoy. Las etiquetas pasan por el índice, no por lo que el agente teclee en el momento.
El bucle “le pedí al agente que capturase una nota” → “la nota está en el sitio correcto con la forma correcta” se vuelve fiable. Las sesiones de limpieza dominicales paran. El vault se mantiene limpio automáticamente. Aburrido, en el buen sentido.
Portabilidad de agentes
Dejas de escribir archivos de instrucciones. Cada agente con MCP obtiene automáticamente el mismo contrato del vault. Cambia de Claude Code a Codex, las convenciones aguantan. Añade OpenCode a la mezcla porque quieres un flujo TUI, las convenciones aguantan. Sale un agente nuevo el año que viene con capacidades que Claude no tiene, lo apuntas a brainkeeper, las convenciones aguantan.
El coste de migración pasa de “reescribir todas mis convenciones en la sintaxis de este agente” a “registrar un servidor MCP”.
Un ecosistema de herramientas (o el inicio de uno)
La spec es un documento público. Cualquiera puede construir para ella. Una UI web para navegar tu vault que respeta la spec. Una herramienta de migración que importa tu export antiguo de Notion a un vault con forma de brainkeeper. Una herramienta de backup que entiende las reglas de ciclo de vida. Un linter que corre en tu editor y marca violaciones de la spec mientras escribes. Ninguno de ellos necesita el permiso de brainkeeper. Solo necesitan leer SPEC.md y seguir las reglas.
Esta es la parte que más me ilusiona y la parte con más incertidumbre. brainkeeper hoy es un proyecto v0.1.1. Si el ecosistema aparece de verdad depende de si la spec es lo bastante buena como para construir sobre ella, y eso es de las cosas que tardan años en saberse.
Longevidad de los datos
Tu vault es una carpeta de archivos Markdown planos con YAML frontmatter. brainkeeper tiene licencia MIT. La spec está en un repo público. La implementación de referencia está en PyPI. No hay SaaS de por medio, ni proveedor de auth, ni rate limit de API, ni términos de servicio que puedan cambiar. Si brainkeeper como proyecto desapareciera mañana, tu vault seguiría abriéndose en cualquier editor de texto y tus convenciones seguirían documentadas en un Markdown que tú controlas.
Esta es la misma propiedad que hizo ganar a Markdown. El formato es tuyo. Los datos son tuyos. El protocolo que opera sobre ellos es abierto. Nada de aquí puede ser apagado, deprecado o cerrado.
FAQ
¿Esto reemplaza a Obsidian?
No. brainkeeper es la capa de acceso para IA; Obsidian es la capa de acceso humano. Son complementarias. Tu vault en disco es el mismo. Obsidian lo abre normal. El servidor MCP da a los agentes de IA una interfaz estructurada que respeta los mismos archivos. Usa los dos.
¿Por qué MCP y no una API REST?
Porque cada agente de IA moderno habla MCP. Claude Code, Claude Desktop, Codex, OpenCode, Cursor; todos ellos registran servidores MCP como una capacidad de primera clase. Una API REST forzaría a cada agente a escribir una integración a medida; MCP es la lingua franca.
¿Por qué Python?
La implementación de referencia es Python porque Python es lo que escribo más rápido. La spec es agnóstica al lenguaje. Una implementación en Rust o TypeScript sería bienvenida.
¿Puedo usarlo sin agentes de IA?
Sí. La CLI sola es útil. brainkeeper init inicializa un vault. La librería Python está expuesta para quien quiera escribir su propio tooling.
¿Qué pasa con estructuras de carpetas que no sean PARA?
Seis capas son el default. La spec te deja renombrarlas en brainkeeper.yaml y extender con carpetas adicionales al lado. La restricción es que las seis layer keys canónicas existan y enruten a algún sitio.